
Назначение тега canonical
С помощью тега <link rel=»canonical» href=»http://example.com/»> можно указать поисковым системам, какой URL-адрес страницы считается каноническим (предпочтительным).
Тег или атрибут canonical служит для предотвращения дублирования контента в поисковых системах, т.к. из-за особенностей работы интернет-сайтов один и тот же контент (статья, товар, листинг) может выдаваться по разным URL-адресам.
Популярные примеры дублирования контента:
- товар или статья доступная в разных категориях
- страницы фильтрации
- страницы с параметрами в URL
Примеры:
https://example.com/category1/tovar1
https://example.com/category2/tovar1
https://example.com/category1/
https://example.com/category1/?color=red
https://example.com/category1/?from=site
Проблему с дублями страниц необходимо решать в обязательном порядке потому-что:
- Если не указать явно предпочтительный адрес, поисковая система будет выбирать его на свое усмотрение и будет показывать в результатах поиска
- Чтобы связать информацию о ссылках, переходах и поведении пользователей с одним URL. То есть информация по всем копиям будет учитываться для основного URL, это крайне важно для SEO.
- Чтобы упростить сканирование сайта для поисковых систем. Робот не тратит время на переход по неканоническим страницам и может обходить чаще канонические.
Как указать каноническую страницу
Два явных способа указания канонического URL:
- Основной и самый популярный — с помощью тега
<link rel=»canonical» href=»http://example.com/»>
2. С помощью HTTP заголовка, в поле Link:
Link: http://www.example.com/downloads/white-paper.pdf; rel=»canonical»
Также, поисковые системы могут отдать предпочтение определенной странице, если:
- страница указана в карте сайта
- с дублей страниц стоят 301 редиректы на основную страницу
- на нее стоят внутренние и/или внешние ссылки
То есть, если робот поисковика нашел две одинаковых страницы, то предпочтет ту, которая указана в карте сайта, на которую стоят внутренние или внешние ссылки.
Кстати, понимая этот факт, может загнать в индекс дубли страниц у сайта конкурента, проставив на них ссылки с разных источников.
Как проверить каноническую страницу
Если вы можете читать HTML код, то можно поискать в исходном коде страницы. В браузере на открытой вкладке нажмите CTRL+U, или правой кнопкой мыши на странице и «Посмотреть исходный код».

Еще проще установить в браузер специальное расширение с SEO функционалом, их очень много разных. Из тех, что я пользуюсь, сразу несколько показывают тег canonical: SEO Meta Inspector, SEO minion, Robots Exclusion Checker и Link Redirect Trace

Какую страницу считает канонической поисковик?
Даже если вы указали в коде тег canonical, поисковик может выбрать канонической другую страницу. Чаще всего это происходит из-за ошибок в коде со стороны веб-мастера, но бывает поисковик выбирает каноническую на основе внешних сигналов, которые считает сильней, чем указания вебмастера.
В Яндекс и Google в кабинете вебмастера есть инструменты, где можно проверить URL и получить информацию.
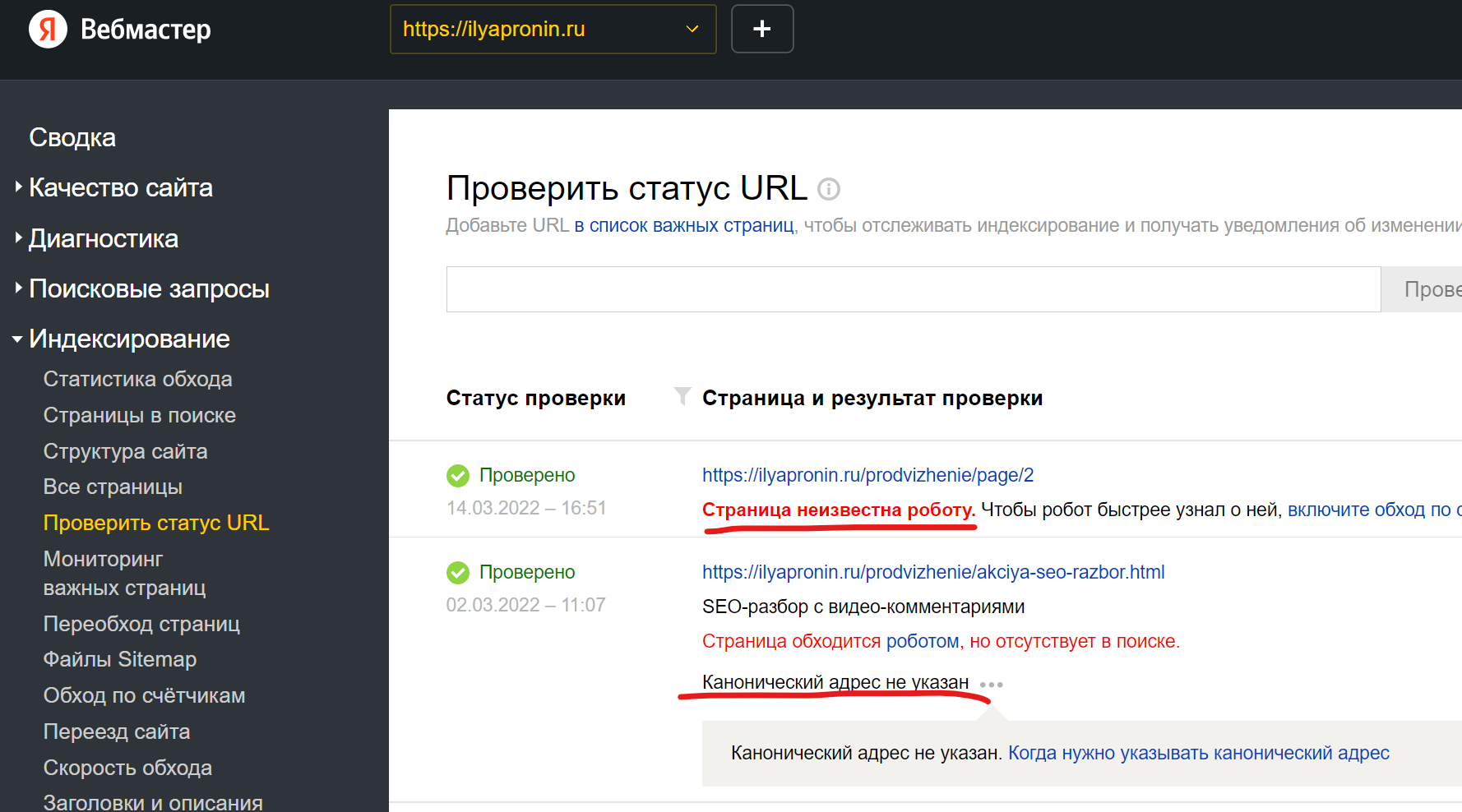
Как массово проверить сайт на наличие canonical
Можно использовать почти любые программы или веб-сервисы для SEO-анализа сайта, они все наверняка будут показывать информацию по тегам canonical.
Из программ рекомендую бесплатную SiteAnalyzer, а из сервисов SERanking, который тоже бесплатен для сайтов до 1000 страниц (а если больше, то все равно дешево).
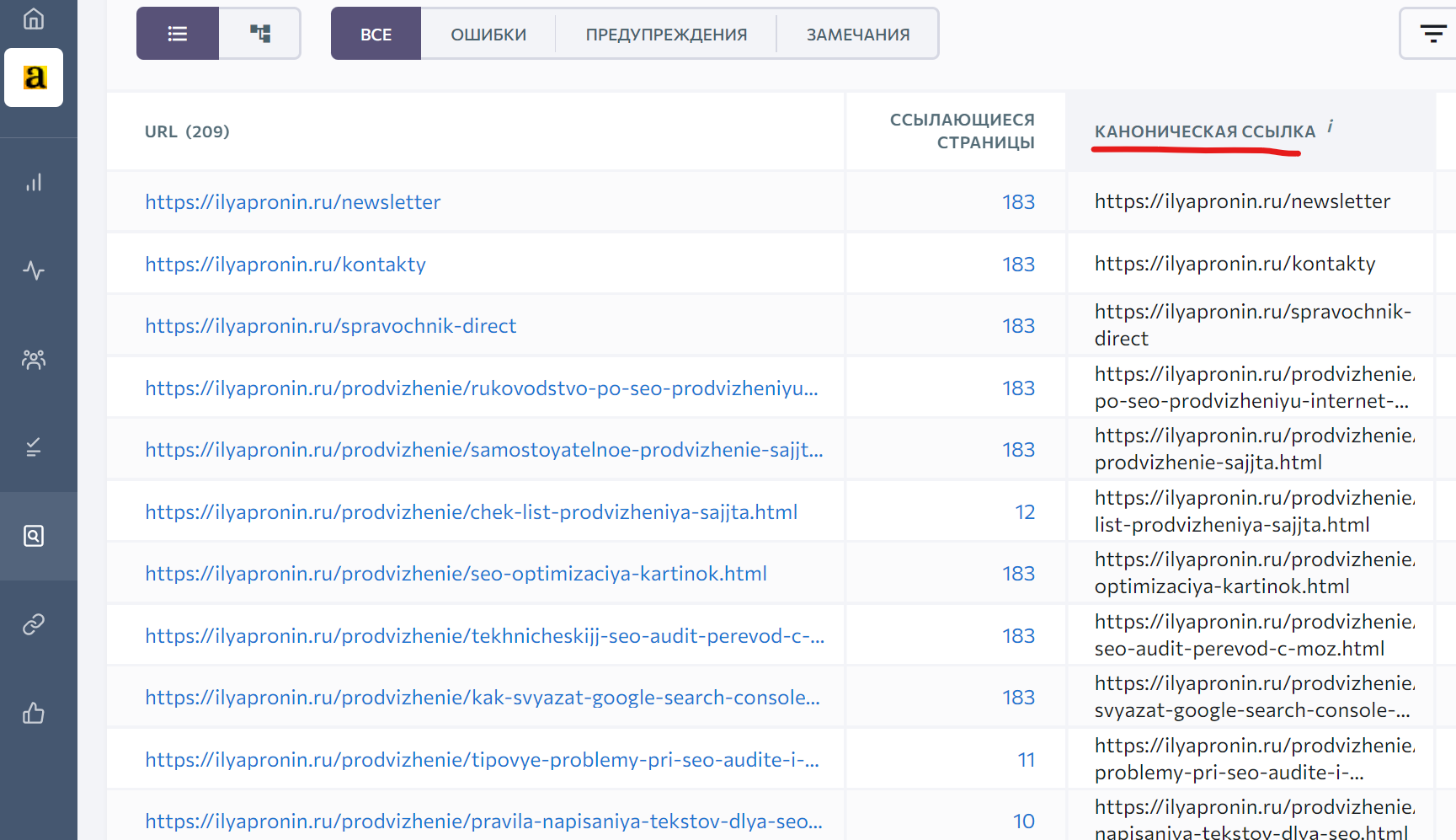
Предпочитаю сервисы, потому-что не надо ничего устанавливать и отчеты доступны с любого компьютера.
Как помочь поисковым системам индексировать нужные страницы
Самый частый тип дублей, это страницы с параметрами в адресной строке. С параметрами, которые не влияют на содержимое страницы, например используемых для статистики, или меняющих способ отображение информации в браузере.
Популярная ошибка веб-мастеров просто закрывать такие страницы от индексации, но в таком случае отбрасываются (или не учитываются) показатели, накопленные по таким URL в поисковых системах.
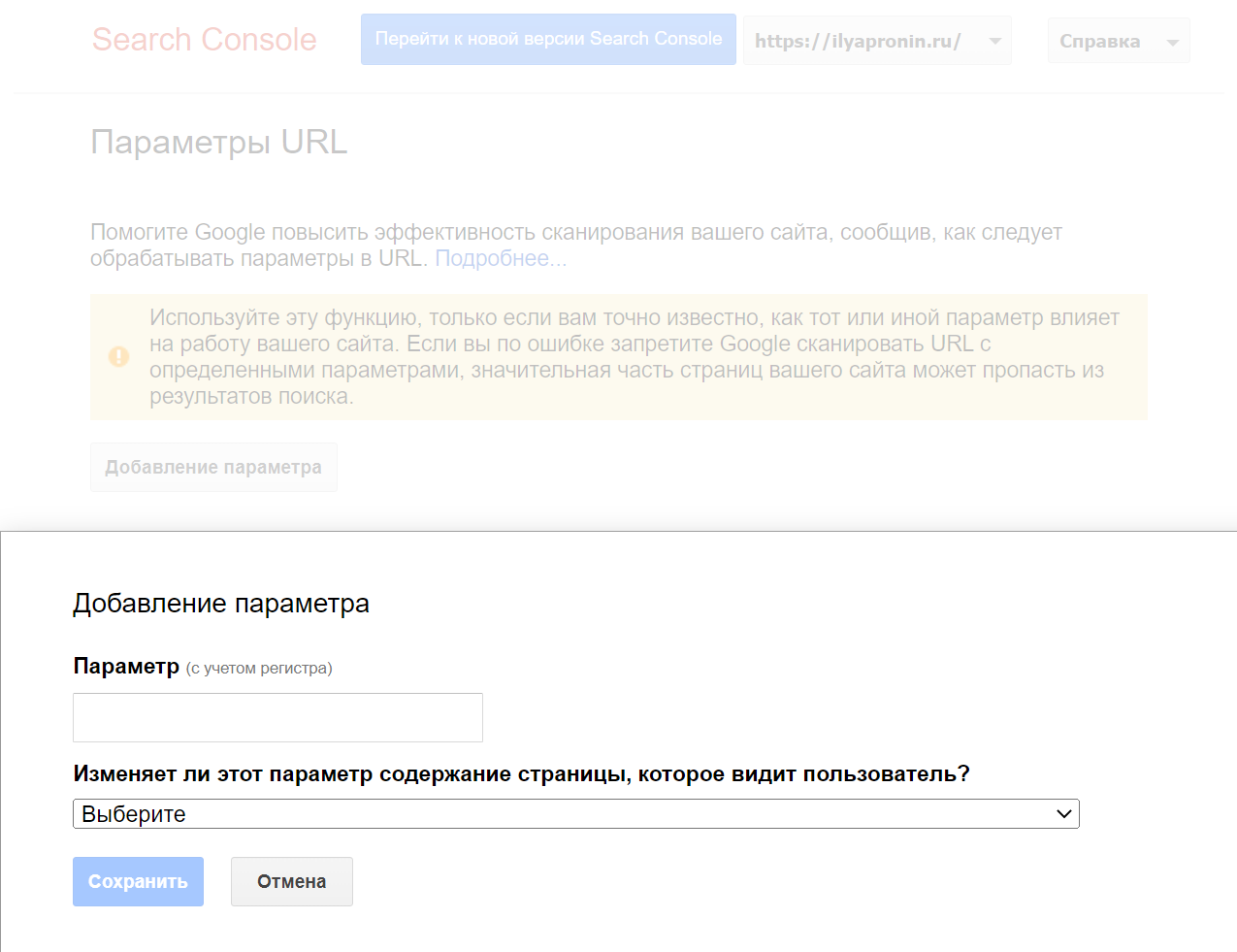
В Яндексе для этих целей есть специальная директива Clean-Param, а в Google в Google Search Console специальный инструмент для указания параметров, которые надо отбросить.
Например, на сайте есть страницы:
www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_3&book_id=123Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
User-agent: Yandex
Disallow:
Clean-param: ref /some_dir/get_book.plРобот Яндекса сведет все адреса страницы к одному:
www.example.com/some_dir/get_book.pl?book_id=123А в Google надо будет добавить параметр ref в инструменте «Параметры URL»
Canonical на саму себя
Некоторые владельцы сайтов задаются вопросов, правильно ли делать тег canonical указывающий сам на себя. Это нормальная ситуация, тем большее, если канонический адрес добавляется с помощью какого-то модуля, то врядли у вас получится сделать так, чтобы он проставлял выборочно.
Кроме того, представитель Google, Джон Мюллер, говорит о том, что он даже желателен.
«Наличие канонического тега на странице указывающего на себя не критично, но это облегчает нам выбор именно того URL, который вы хотите выбрать в качестве канонического.
Мы используем ряд факторов для выбора канонического URL, и rel-canonical играет в этом не последнюю роль.
Так, в частности, такие вещи, как параметры URL, или если URL помечен каким-либо особым образом — возможно, у вас есть ссылки, ведущие на эту страницу, которые помечены для аналитики, например — тогда может случиться так, что мы выберем этот помеченный и с параметрами URL в качестве канонического.
А с помощью rel-canonical вы говорите нам, что вам очень, очень нужен именно этот URL, который вы указываете в качестве канонического…
Так что это отличная практика — иметь самоссылающийся канонический URL, но это не критично. Это не то, что необходимо это просто то, что помогает убедиться, что эта разметка будет воспринята правильно».
Джон Мюллер, на 28й минуте https://www.youtube.com/watch?v=MD6ABXMMuaI
Больше всего споров возникает о том, как настраивать тег canonical в интернет-магазинах и каталогах для постраничной навигации. Чаще всего предлагаются такие варианты:
- Оставить каноническими все страницы категории.
- Делать канонической первую страницу категории.
- Делать канонической страницу, на которой выводятся все товары (category?view=all), при этом не каждый движок это может сделать по умолчанию.
- Использовать теги rel=»next» и rel=»prev», чтобы указать поисковым системам на страничную навигацию. Но эти теги никогда не поддерживал Яндекс, а в 2020 году Google заявил, что они давно не обращают на них внимание.
Пример разметки rel=»next» и rel=»prev» для 2й страницы в категории:
<link rel="next" href="https://website.com/page/3/> <link rel="prev" href="https://website.com/page/1/>
Споров вокруг этой темы много, но самое главное, нет никаких тестов и исследований, которые бы показали преимущества или недостатки какого-то способа. Представители Google вообще чаще всего предлагают не заморачиваться, утверждая, что робот разберется.
Я еще не видел, чтобы изменение этой настройки хоть как-то заметно повлияло на трафик, хотя чисто технически можно спорить и считать ошибкой вариант, который вам не нравится.
Однако, лучше избегать таких настроек:
- Ни в коем случае нельзя закрывать от индексации страницы категории. В таком случае поисковик не сможет учитывать показатели таких URL (например, не будет передаваться PageRank), а товары с исключенных страниц в некоторых случаях не попадают в индекс (например, если ссылка на товар есть только на 3й странице категории).
- Все таки не стоит указывать канонической первую страницу. Может получится эффект такой же как от закрытия индексации, 2я и далее страницы категории могут выпасть из индекса. Но хотя бы уже не теряются сигналы и ссылки, т.к. rel-canonical сольет их на первую страницу.
Еще вот хорошая инфографика от Ahrefs:

Рекомендации по использованию тега canonical
Простые правила, которые сократят вероятность ошибок.
- Используйте только абсолютные адреса в теге canonical. Тогда по какому бы адресу не была открыта страница, она будет всегда указывать на один и тот-же адрес.
- Частный случай п.1 Используйте правильную версию протокола HTTPS или HTTP
- Канонический URL должен быть открыт к индексации и отдавать код сервера 200 ОК.
- Ставьте внутренние ссылки (из меню, из контента) на канонические адреса, в противном случае вы даете поисковым системам противоречащую информацию.
- Прописывайте адреса в нижнем регистре
- Используйте тег canical на всех страницах сайта. Какой смысл настраивать для отдельных страниц, ваш движок должен проставлять правильный canonical для всех страниц (и ссылка на саму себя не проблема, а наоборот преимущество, как мы уже рассмотрели в статье).
- Используйте единственный на странице тег canonical, иначе поисковик проигнорирует все.
- Не закрывайте от индексации неканонические страницы
Сanonical или noindex?
Многие вебмастера закрывают от индексации неканонические страницы через robots.txt или метатегом noindex.
Во первых, в этом нет смысла, т.к. уже указали каноническую страницу, робот-краулер поймет, что остальные не надо индексировать.
Во вторых, так теряются сигналы для неканоничных URL, которые могут учитывать поисковые системы. Все таки noindex служит главным образом для закрытие контента, который нежелательно индексировать, а не для закрытия дублей)
Допустимо закрывать дубли страниц от индексации, если нет возможности настроить канонические адреса.
Скрытые ошибки с canonical
«Мнимый» canonical
Много раз сталкивался с ситуацией, когда добавляют теги canonical, при этом на дублирующихся страницах стоит canonical на себя. В таком случает, при выборочной проверке кажется, что везде прописаны canonical, а проблему тяжело обнаружить.
То есть:
Страница
example.com/page1
содержит canonical
example.com/page1
Ее дубль
example.com/news/page1
содержит canonical
example.com/news/page1
То есть фактически движок прописывает в каноникал текущий URL, и по какому бы URL не открыть страницу у нее будет стоять такой же canonical. В итоге получается такая же ситуация как вообще без указания канонических страниц, но еще и поисковики сбиты с толку.
«Плавающий» canonical
В движках, где товар или статья может быть в нескольких категориях должен быть явный способ обозначения главной категории, которая и будет использоваться в каноническом адресе.
На практике были случаи, когда канонические адреса менялись время от времени, возможно после операций импорта/экспорта или редактирования.
То есть:
У товара:
example.com/category1/tovar1
сегодня canonical
example.com/category1/tovar1
а завтра
example.com/category2/tovar1
Передача ссылочного веса через canonical
Специально отдельно это отмечу и вынесу отдельным блоком. Неканонические адреса страниц могут собирать ссылочный вес и передавать канонической странице.
Об этом также явно сказано в справке Google:
Для консолидации сигналов ссылок для похожих или дублирующихся страниц. Это помогает поисковым системам консолидировать информацию, которую они имеют для отдельных URL (например, ссылки на них), в единый, предпочтительный URL. Это означает, что ссылки с других сайтов на http://example.com/dresses/cocktail?gclid=ABCD объединяются со ссылками на https://www.example.com/dresses/green/greendress.html.
Google, перевод с https://developers.google.com/search/docs/advanced/crawling/consolidate-duplicate-urls?hl=en
Другие вопросы
Если у вас есть интересный вопрос или ситуация с canonical, то напишите в комментариях или мне на почту.



